tensor-native-processor.github.io
Latest News
- Added Final Report! :D
- Added a Milestone Report section at the end and a doc link.
Title
Accelerate tensor operations via tensor native processor
Writeups
URL
https://tensor-native-processor.github.io/
Summary
We are going to develop a tensor native processor and a compiler to accelerate tensor operations, such as tensor multiplication.
Background
We want to create a new tensor processor that is native to tensor operations. Compared to existing tensor processors, we want to make the following improvements to increase throughput:
- Cache can be organized into matrices to optimize them for tensor operations and instructions. For example, we can transpose a matrix in cache in one clock cycle, which reduces the penalty of matrix transpose.
- To maximize the utilization of systolic arrays, local caches should be able to read data in a diagonal way in one clock cycle.
- Cache should be able to read and write two diagonals simultaneously to keep the systolic array at full utilization.
- Since the computation is static, we can let compilers generate instructions that explicitly manage the cache, instead of LRU. And we can let compilers generate simultaneous instruction streams for each matrix unit for more intelligent work assignment.
- To simplify the matrix core design and leave more transistor area for arithmetic operations, we use the interconnect in a MPI-like way. Then there’s no cache coherence problem and compilers decide when to communicate.
- To implement these improvements, we will design a new compiler and simulator to generate instructions from a given problem, and estimate the time required to complete computation.
The Challenge
This problem has the following challenges:
- Work assignment in the compiler is hard. We need to assign individual instructions to different cores, and we want to keep the workload balanced to maximize throughput and prevent cores from stalling. This will require using simulators in a feedback way to generate optimal simultaneous instruction streams. But we need to find out how to use the simulator information.
- Cache assignment is also hard. Compilers need to explicitly determine the location of each matrix (essentially determining when to evict matrices) and when to communicate with other cores or read/write data to DRAM. This requires an overall understanding of how individual matrices are used throughout the execution lifecycle.
- The compiler has to scale over multiple matrix cores, multiple processors or multiple systems. So we need to design an algorithm for the compiler that scales well.
- We need to determine the width of matrix cores (for example, 128x128). Small width leads to low throughput, and large width leads to low utilization and wasted transistor area.
- We need to determine how many matrix cores lead to an overall good performance. This would be helpful to create a processor that is competitive in most workloads.
Resources
- Code base: we will be starting from scratch.
- Computing: we will be using GHC machines.
Goals and Deliverables
- PLAN TO ACHIEVE
- A native tensor processor written in Verilog.
- A simulator that accurately returns the estimated time for our processor to perform various tensor operations.
- A compiler that transforms tensor operations into instruction streams.
- Performance analyses of various work assignment strategies across different tensor operations, sizes and dimensions.
- HOPE TO ACHIEVE
- A compiler that transforms PyTorch/Tensorflow computation graphs into instruction streams.
- Performance analyses of different work assignment strategies across various neural network architectures.
Platform Choice
- We will use C++ to program the compiler and simulator. C++ is used because we need to measure the performance from a large amount of data, and use Linux syscalls to exchange data across different components.
- We will use Synopsys VCS to simulate hardware descriptions. VCS is used because we want an accurate simulation result to make sure that the hardware works correctly, so the C++ simulator returns a valid estimation of time consumed.
Schedule
Week
- 11/14: Instruction format; hardware description for matrix/vector cores; simulator
- 11/21: Simulator; compiler
- 11/28: Compiler; performance analyses of various work assignment strategies
- 11/30: Milestone Report
- 12/5: Performance analyses; stretch goals
- 12/12: Buffer; stretch goals
- 12/17: Final Report
- 12/18: Poster Session
Milestone Report
Schedule
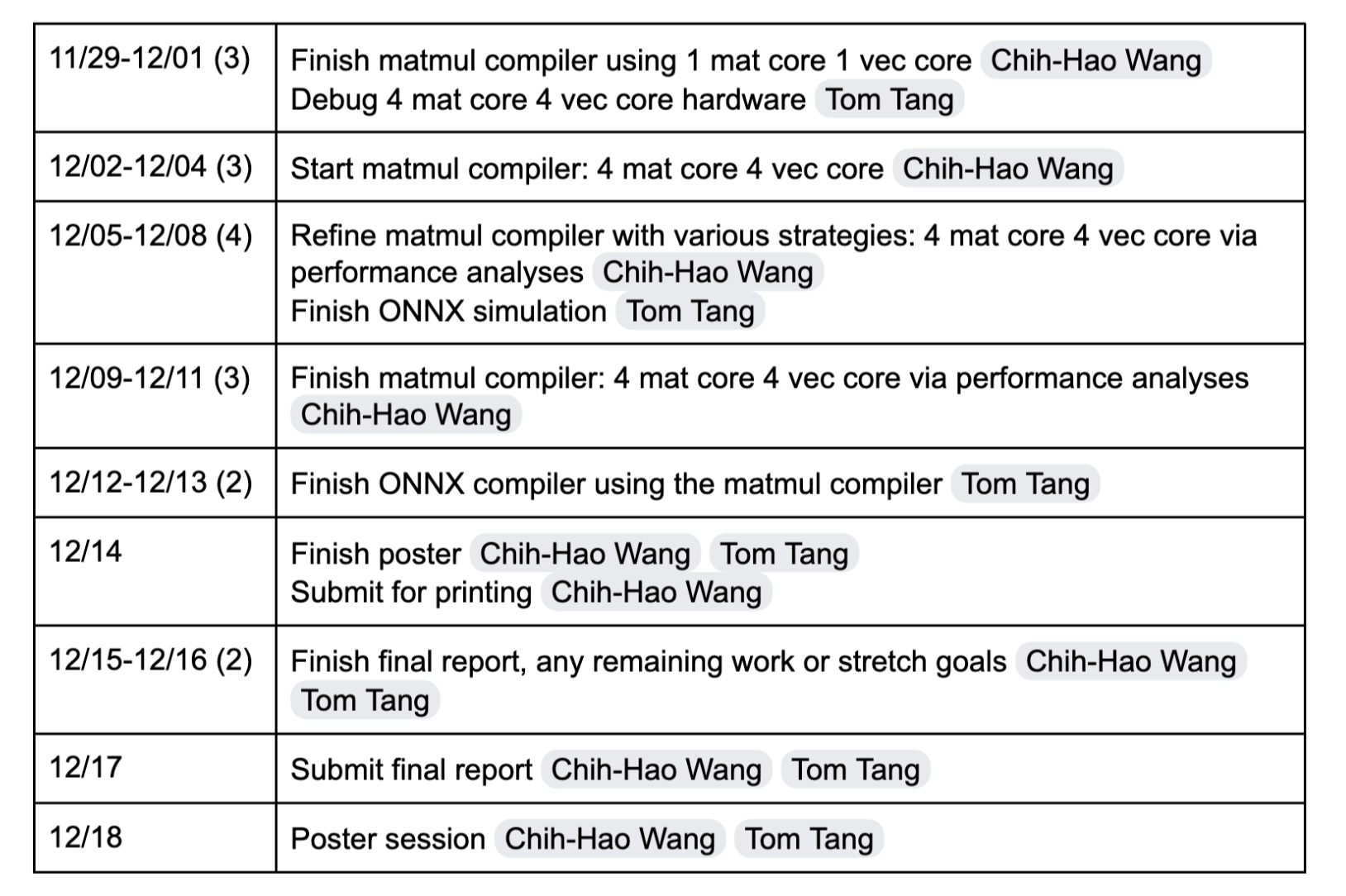
Summarization of work completed so far
We have written a native tensor processor in Verilog, a simulator that returns the number of cycles performed given a compiled program, and some sample programs performing operations on a single core.
How we are doing with respect to the goals and deliverables stated in our proposal
We are on schedule and believe we will be able to produce all “plan to achieve” deliverables. We should be able to produce a portion of “hope to achieve” deliverables by targeting the inference of a simple neural network (only involving Gemm and ReLU).
Things we plan to show at the poster session
- ACHIEVED
- Architecture and instruction diagrams of our tensor native processor.
- PLAN TO ACHIEVE
- A table showing performance analyses of matrix multiplication
- single core
- multi-core
- different compiler/work assignment strategies
- A table showing performance analyses of matrix multiplication
- HOPE TO ACHIEVE
- A table showing performance analyses of simple neural network inference
- single core
- multi-core
- different compiler/work assignment strategies
- A table showing performance analyses of simple neural network inference
Preliminary results
- Simulation results on u-16m1-16v1 hardware.
- u-16m1-16v1 means uniform with one 16*16 matrix core and one 16 vector core.
- ADD(v16, v16) means performing addition of two 16 vectors.
- MULT(m16, m16) means performing matrix multiplication on two 16*16 matrices.
| Operations | Simulated Clock Cycles |
|---|---|
| ADD(v16, v16) | 11 |
| MULT(m16, m16) | 122 |
Concerning issues
- High degree of freedom in performance analyses. How to select these values to present interesting findings?
- Varying the hardware cache size and matrix/vector core width
- Different work assignment strategies in the compiler
- When to store data into the registers and which register should it store?
- Potential deadlock in interconnect. Need to be careful with the compiler implementation.